Inference Trace
One of the big challenges for LLM developers is not knowing why the chatbot did what it did.
If you don't know why your AI did what it did, it's hard to know how to fix it.
Athina makes it easy to log, and inspect traces that can help you understand your what went on in your LLM inferences in production.
Prompt-response pairs logged to Athina contain a lot of information, that can be very valuable in debugging.
See the Logging section for details on how to log inferences the right way.
💡
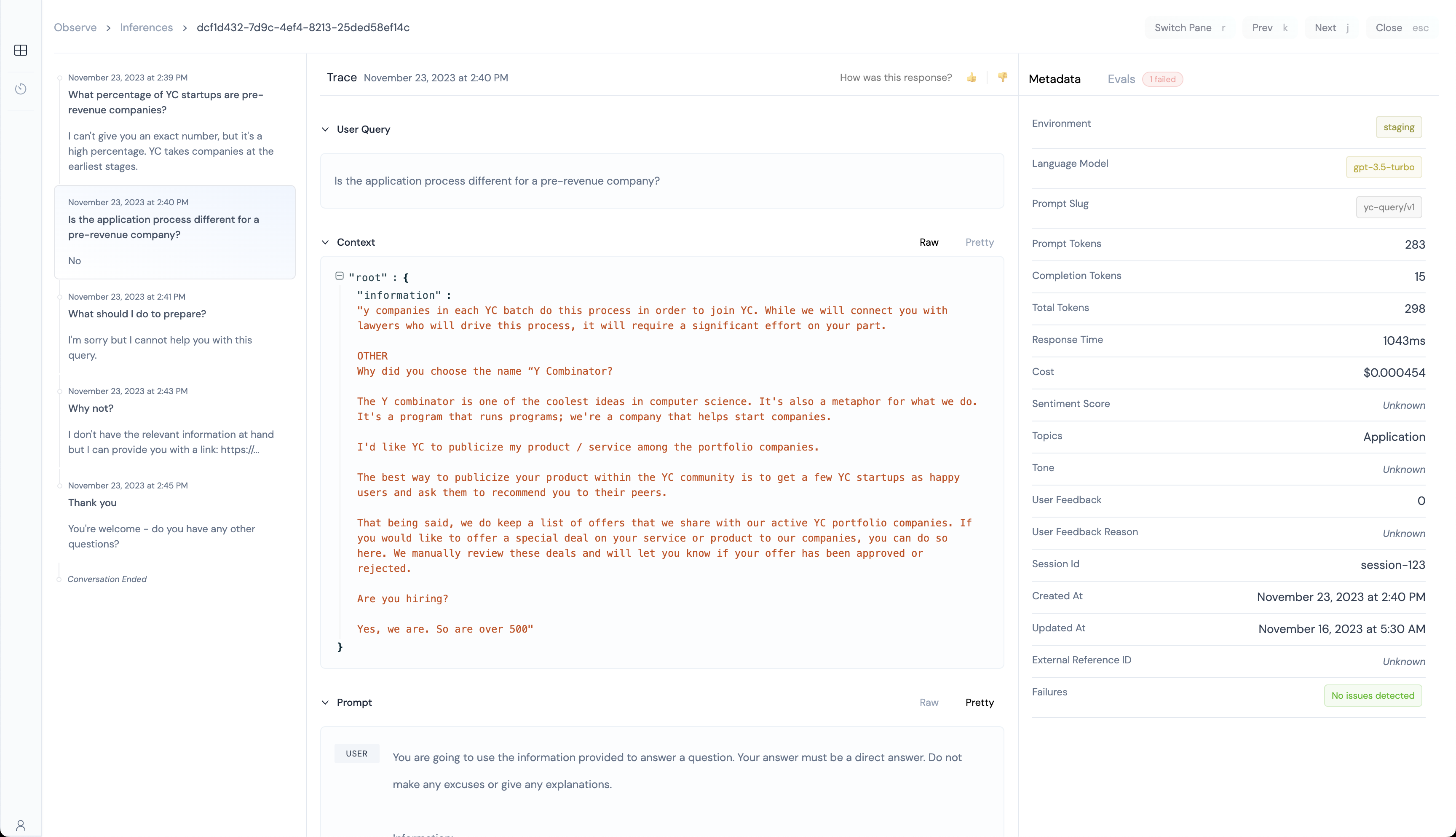
Athina's Inference Trace View shows you the following information:
- Conversation Timeline
- What query did the user ask?
- What context was fetched from your RAG system?
- What was the prompt that was finally sent to the LLM?
- What was the response generated?
In addition, you can also see the following information:
- What was the sentiment score of the user query?
- What was the tone of the user query?
- What topic was the user query about?
- What was the token usage, cost, and response time of the inference?
- Did someone from your team grade this inference with a 👍 or 👎?
- What language model, and prompt version was used for this inference?
- Which user was this inference for?