Challenges with running LLM evaluation in production at scale
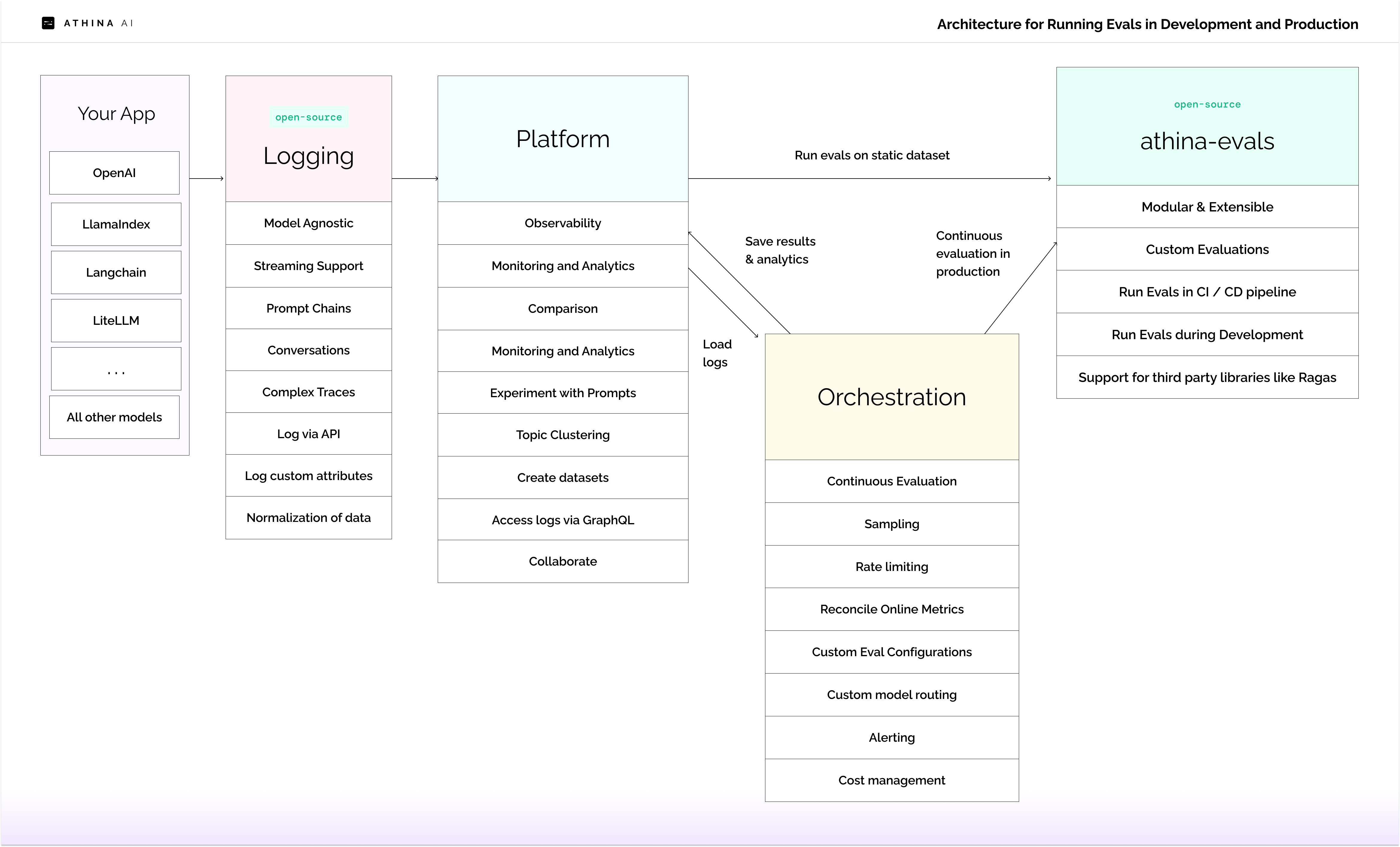
We've spent much of the last year building an orchestration layer for production evaluation of LLM pipelines.
This is a simplified view of the architecture we had to build out to support running evals in production at scale.
Major Challenges
In that time, we learned that there are a LOT of challenges when trying to evaluate LLM outputs in production.
No ground truth in production
Unlike your test dataset in development, production logs don't include any ground truth.
Solution:
- You have to use creative techniques (often using another LLM) to evaluate retrievals and responses without ground truth.
- Keep up with the latest and greatest research techniques to add more evaluation metrics / improve reliability
Cost Management
If you need to use an LLM for evaluation, it can get pretty expensive. Imagine running 5-10 evaluations per production log. The evaluation costs could he higher than the actual task costs!
Solution: Implement sampling + cost tracking mechanism
Automation
Needless to say, running evals in production should be automated and continuous. That poses a number of challenges at scale.
This means:
- You need to scale your evaluation infrastructure to meet your logging throughput
- You need a way to configure evals and store configuration
- You need a way to select which evals should run on which prompts
- You need mechanisms to handle rate limiting
- You need the eval to be run using swappable models / providers
- You need a way to run a newly configured evaluation against old logs
Solution: Build an orchestration layer for evaluation
Athina's eval orchestration layer manages eval configurations, sampling, filtering, deduping, rate limiting, switching between different model providers, alerting, and calculating granular analytics to provide a complete evaluation platform.
You can run Evals during development, in CI / CD, as real-time guardrails, or continuously in production.
Support for different models, architectures, and traces
Say your team wants to switch from OpenAI to Gemini.
Suppose you add a new step to your LLM pipeline.
Maybe you're building an agent, and need to support complex traces?
Maybe you switched from Langchain to Llama Index?
Maybe you're building an chat application and need special evals for that?
Can your logging and evaluation infrastructure support this?
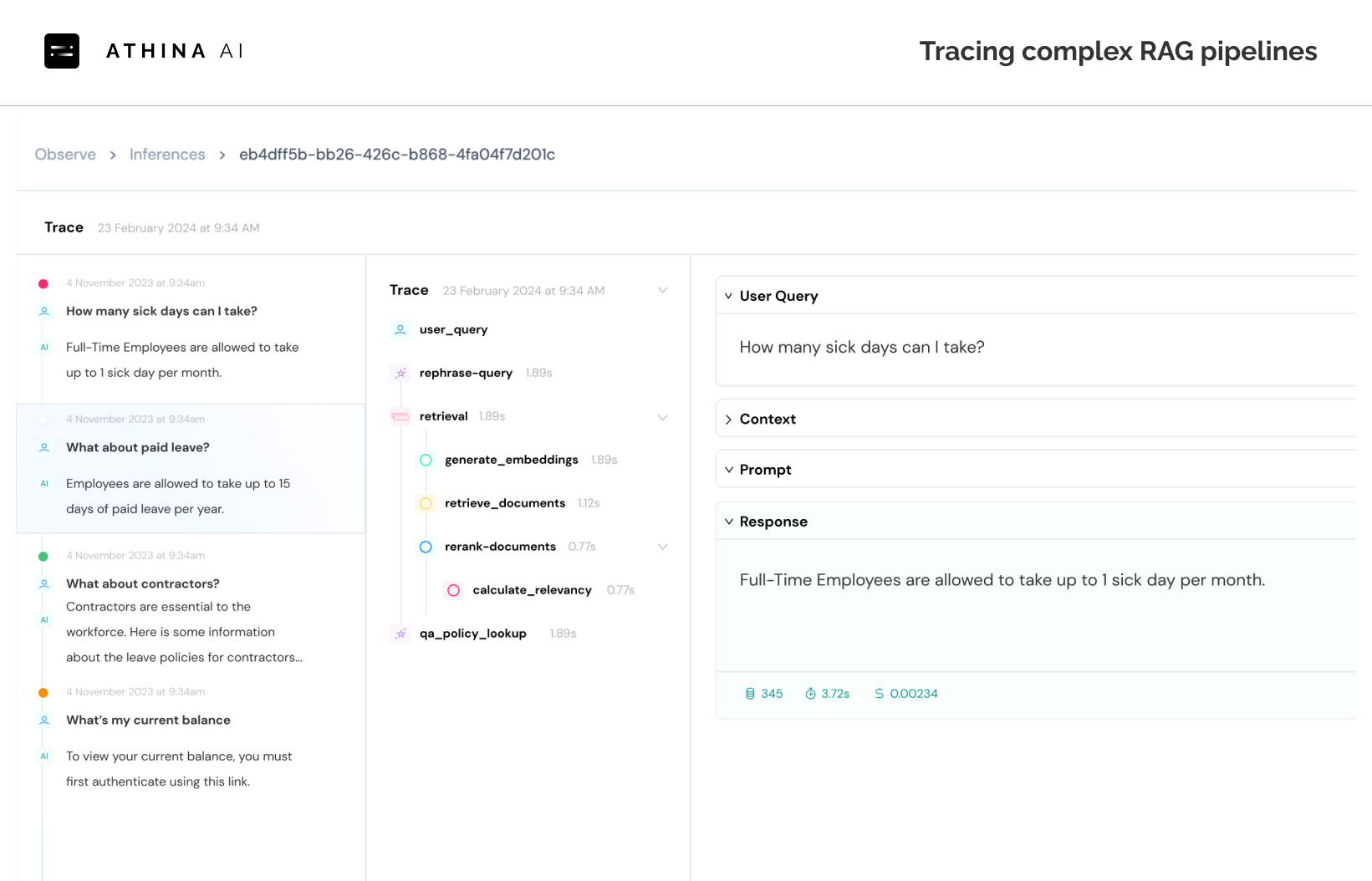
Solution: You need a normalization layer that is separate from your evaluation infrastructure.Inspect and debug complex traces and chats
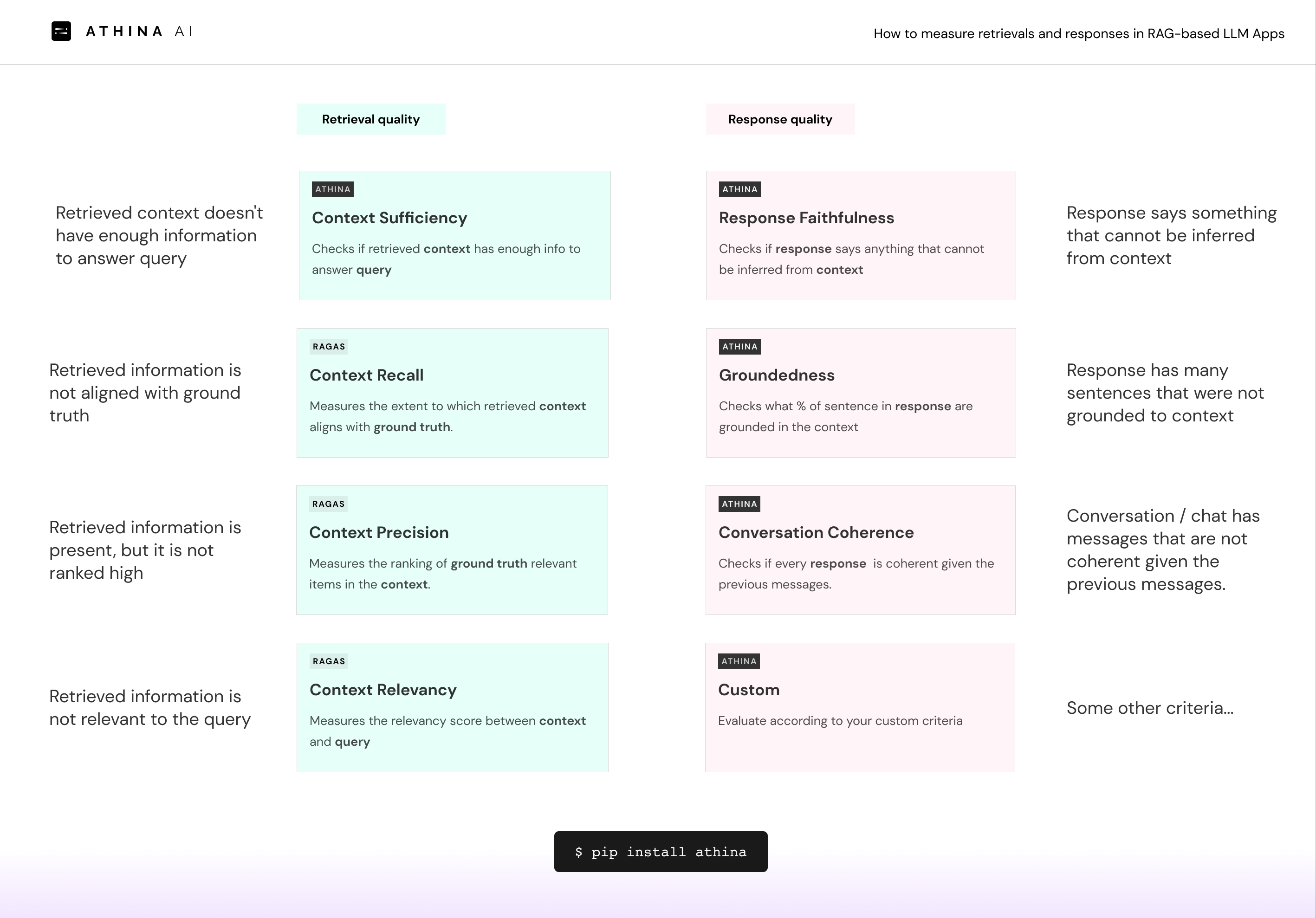
Interpretation & Analytics
What do you do with the eval metrics that were calculated? Ideally, you want to be able to:
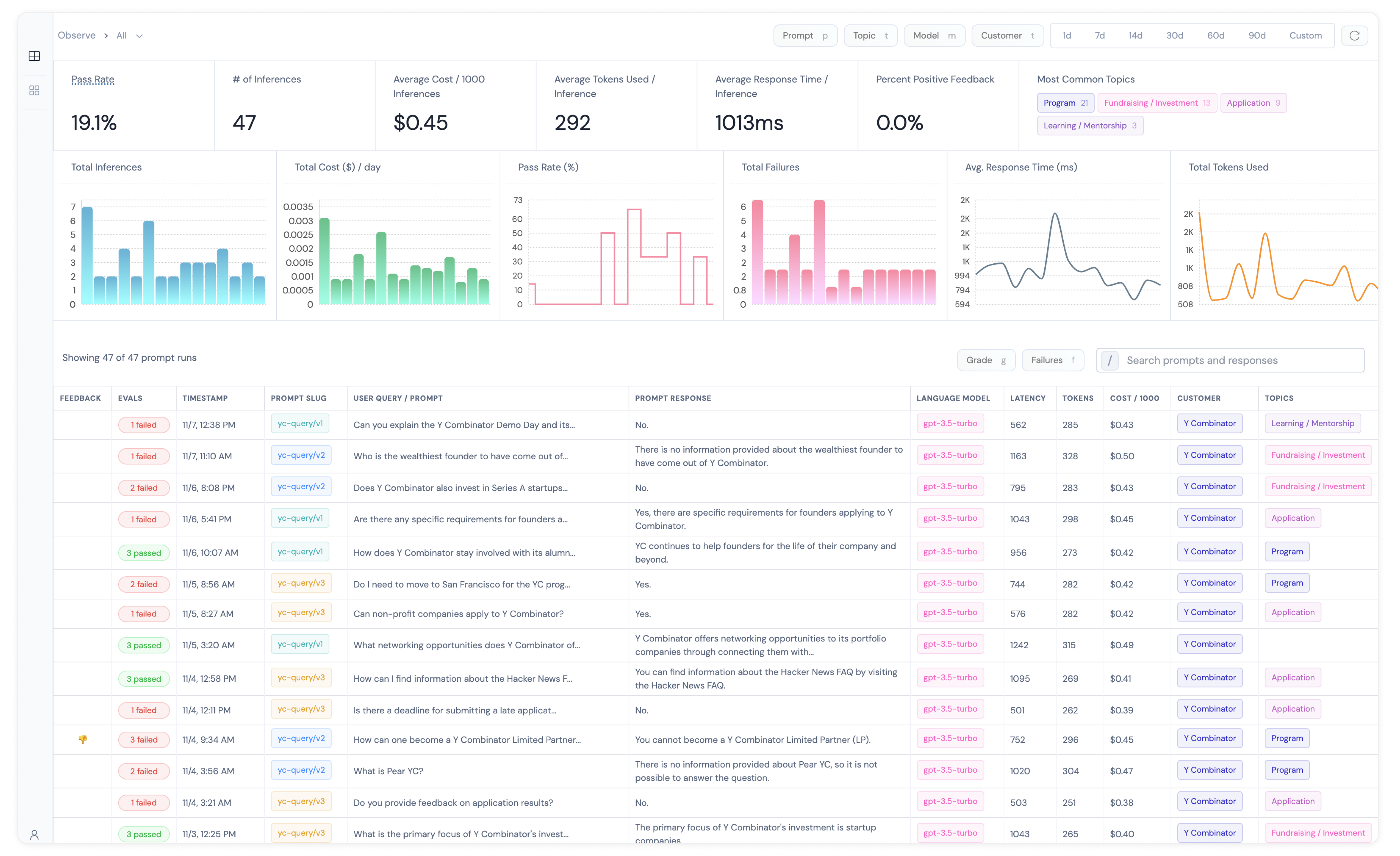
- Measure overall app performance.
- Measure retrieval quality
- Measure usage like token counts, cost, response times
- Measure safety issues like PII leakage or prompt injection attacks.
- Measure changes over time
- Measure distributions of eval scores (p5, p25, p50, p75, p95, etc)
- Segment the metrics by prompt, model, topic or customer ID
Solution: Build an analytics engine that can segment the data, compute these metrics and render them on a dashboard with filter options.
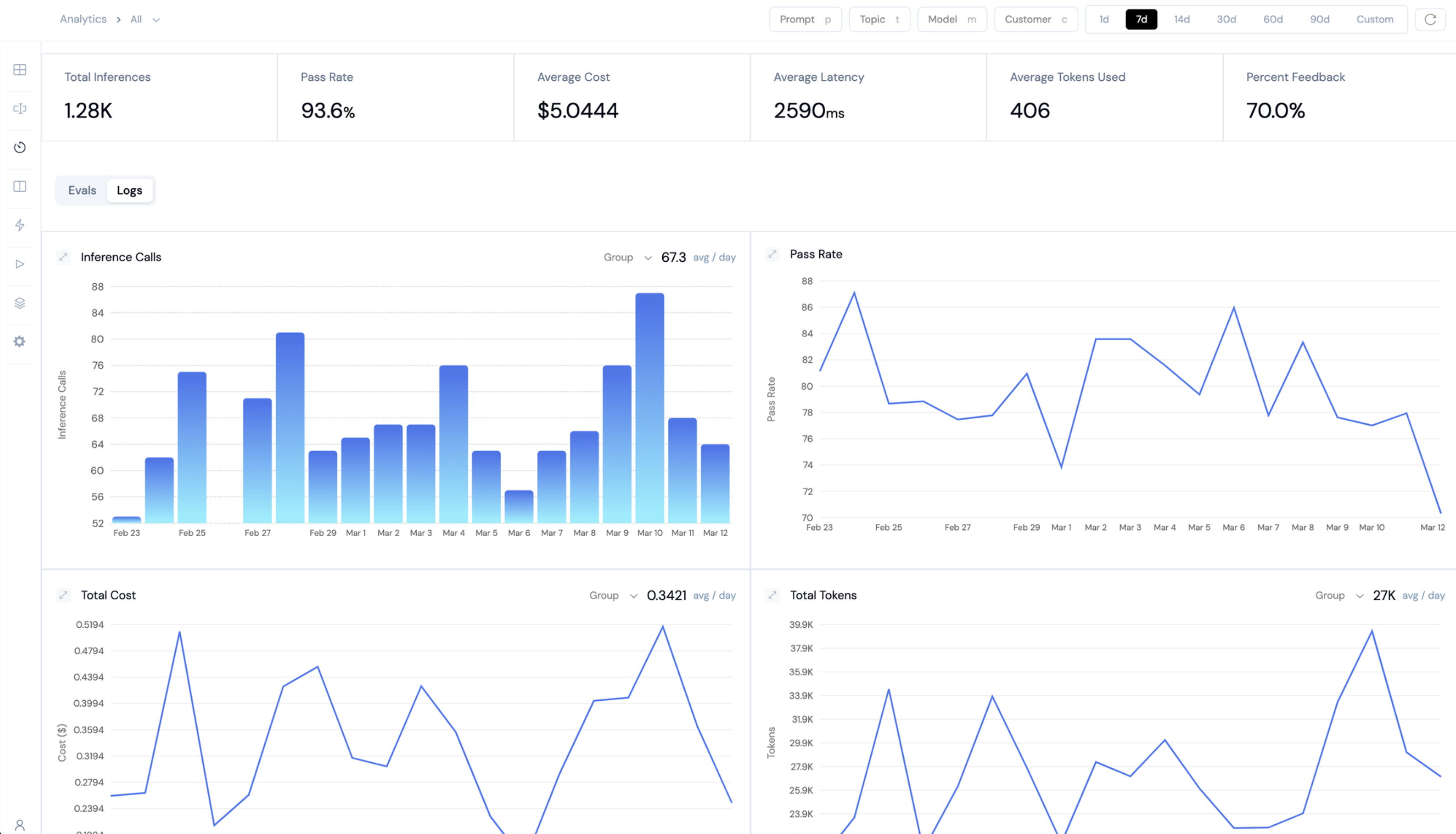
Observability & Alerts
Of course, along with all this, you will also want to be able:
- Manually inspect the traces
- Manually annotate the traces individually
- Consolidate online and offline eval metrics
- Configure alerts to PagerDuty or Slack when failures increase
- Export the data
- Connect to the logs via API / GraphQL
Solution: Build LLM observability platform
Collaboration
The tool you use should also support collaboration features so teammates.
Solution: Build team features, access controls and separation of workspaces.
👋 Athina
We spent a lot of time working through these problems so you don't need a dedicated team for this. You can see a demo video (opens in a new tab) here.
Website: Athina AI (opens in a new tab) (Try our sandbox (opens in a new tab)).
Sign Up (opens in a new tab) for Athina.
Github (opens in a new tab): Run any of our 40+ open source evaluations using our Python SDK to measure your LLM app.