Athina Evals
Preset Evals | Running Evals | Configure Automatic Evals in Production
Systematically Improve LLM Performance with Eval Driven Development
Athina is an evaluation framework (opens in a new tab) designed for LLM developers in any stage from prototype to production to systematically develop, iterate and measure the performance of their LLM application.
Table of Contents
Introduction
Evaluations (evals) play a crucial role in assessing the performance of LLM responses, especially when scaling from prototyping to production.
They are akin to unit tests for LLM applications, allowing developers to:
- Catch and prevent hallucinations and bad outputs
- Measure the performance of model
- Run quantifiable experiments against ambiguous, unstructured text data
- A/B test different models and prompts rapidly
- Detect regressions before they get to production
- Monitor production data with confidence
*Here's a great video (opens in a new tab) by OpenAI where an AI Engineer explains why and how to use evals.
Typical LLM Development Workflows
Here's what typical LLM development workflows look like.
Demo Stage: The Inspect Workflow 🔎
Manual Inspection: Single data point analysis.
- Extremely slow dev cycle
- Low coverage
- Not scalable beyond initial prototyping.
MVP Stage: The Eyeball Workflow 👁️👁️
Spreadsheet Analysis: Multiple data points without ground truth comparison.
- Manual, high-effort, and time-consuming
- No quantitative metrics
- No historical record of prompts run
- You don't have a system to compare the outputs of prompt A vs prompt B
Iteration Stage: The Golden Dataset Workflow 🌟🌟
Systematic Evaluation: Using a golden dataset with expected responses.
- Difficult and time consuming to create good evals
- Requires a mix of manual review + eval metrics
- You need to create lots of internal tooling
- No historical record of prompts run
- Does not capture data variations between your golden dataset and production data
Athina Evals
Athina offers a comprehensive eval system that addresses the limitations of traditional workflows by providing a systematic, quantitative approach to model evaluation.
There are 2 ways to use Athina Evals.
-
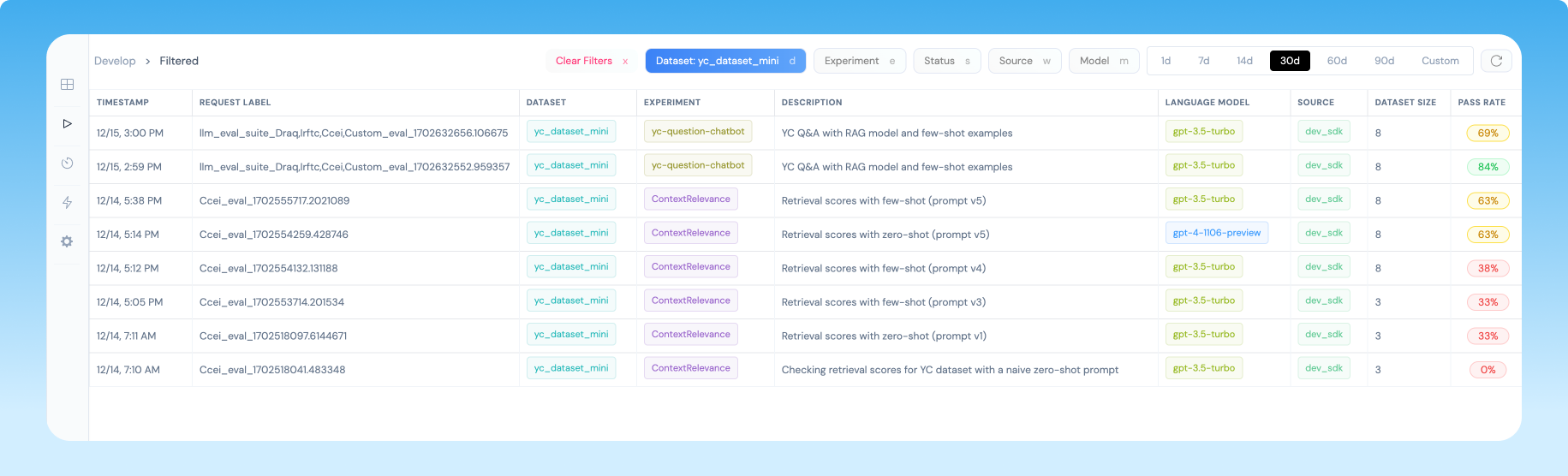
Configure automatic evals in the dashboard: These will run automatically on your logged inferences, and you can view the results in the dashboard.
-
Run evals programmatically using the Python SDK: This is useful for running evals on your own datasets to iterate rapidly during development.
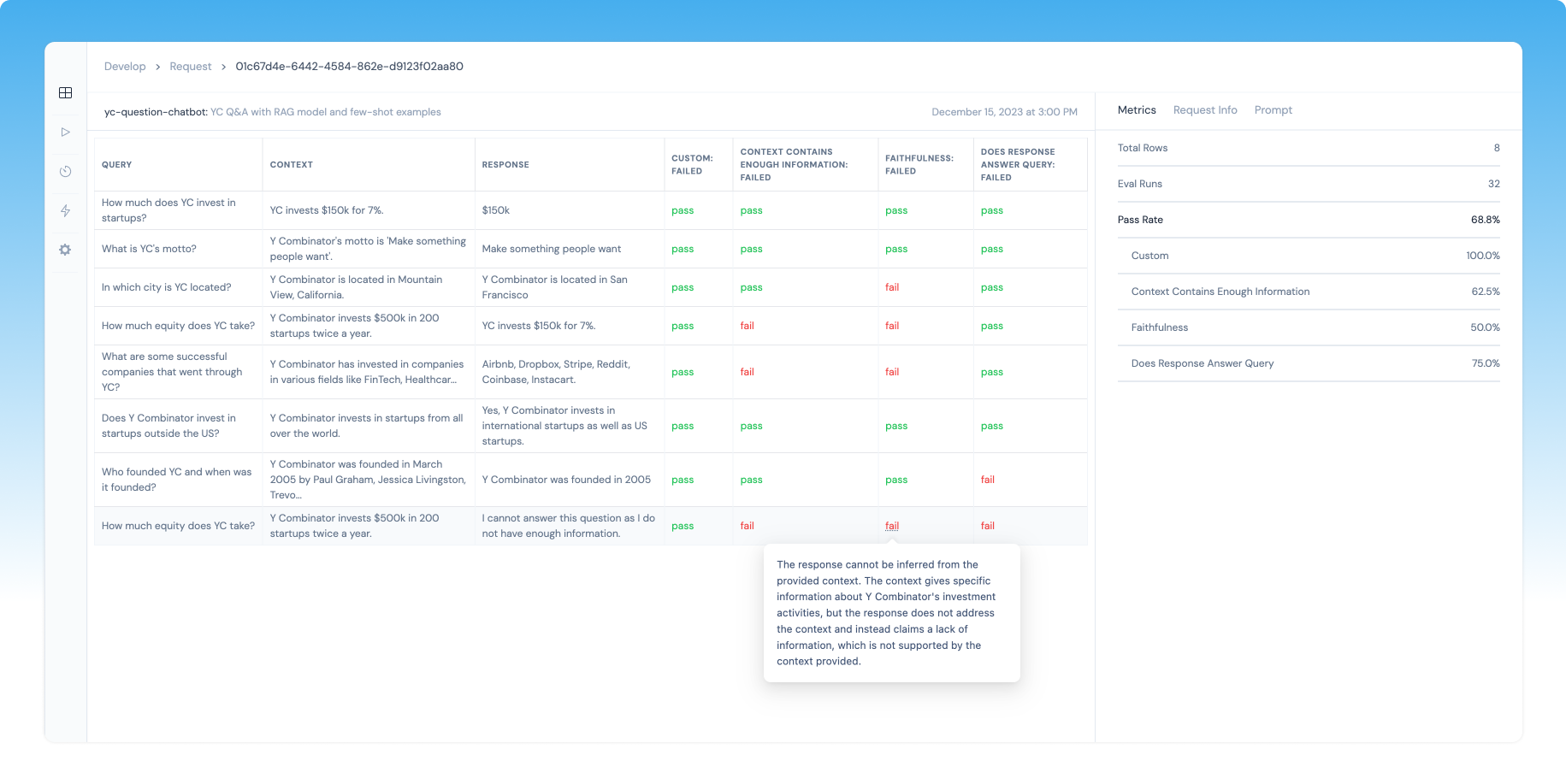
This enables rapid experimentation, performance measurement, and confidence in production monitoring.
- Plug-and-Play Preset Evals: Well-tested evals for immediate use.
- Custom Evaluators: Modular and extensible framework makes it very easy to create custom evals.
- Consistent Metrics: Across development and production.
- Quick Start: 5 lines of code to get started.
- Advanced Analytics: Including pass rate, flakiness, and batch runs.
- Run from anywhere: Run evals in development or production, from a Python file, CLI, or Dashboard.
- Integrated Web Platform: For viewing results and tracking experiments.
The Athina Team is here for you
- We are always improving our evals and platform.
- We work closely with our users, and can even help design custom evals
If you want to talk, book a call (opens in a new tab) with a founder directly, or send us an email at hello@athina.ai.
Athina Evals: Getting Started
- Quick Start
- Preset Evals
- Loading Data for Evals
- Running Evals
- Automatic Evals
- Improving eval performance
- Develop Dashboard
- Cookbooks
FAQs
Athina Evals in your CI/CD Pipeline
You can use Athina evals in your CI/CD pipeline to catch regressions before they get to production. Here's how: