Measuring retrieval and response quality in RAG-based LLMs
Common Failures in RAG-based LLM apps
RAG-based LLM apps are great, but there are always a lot of kinks and imperfections to iron out.
Here are some common ones:
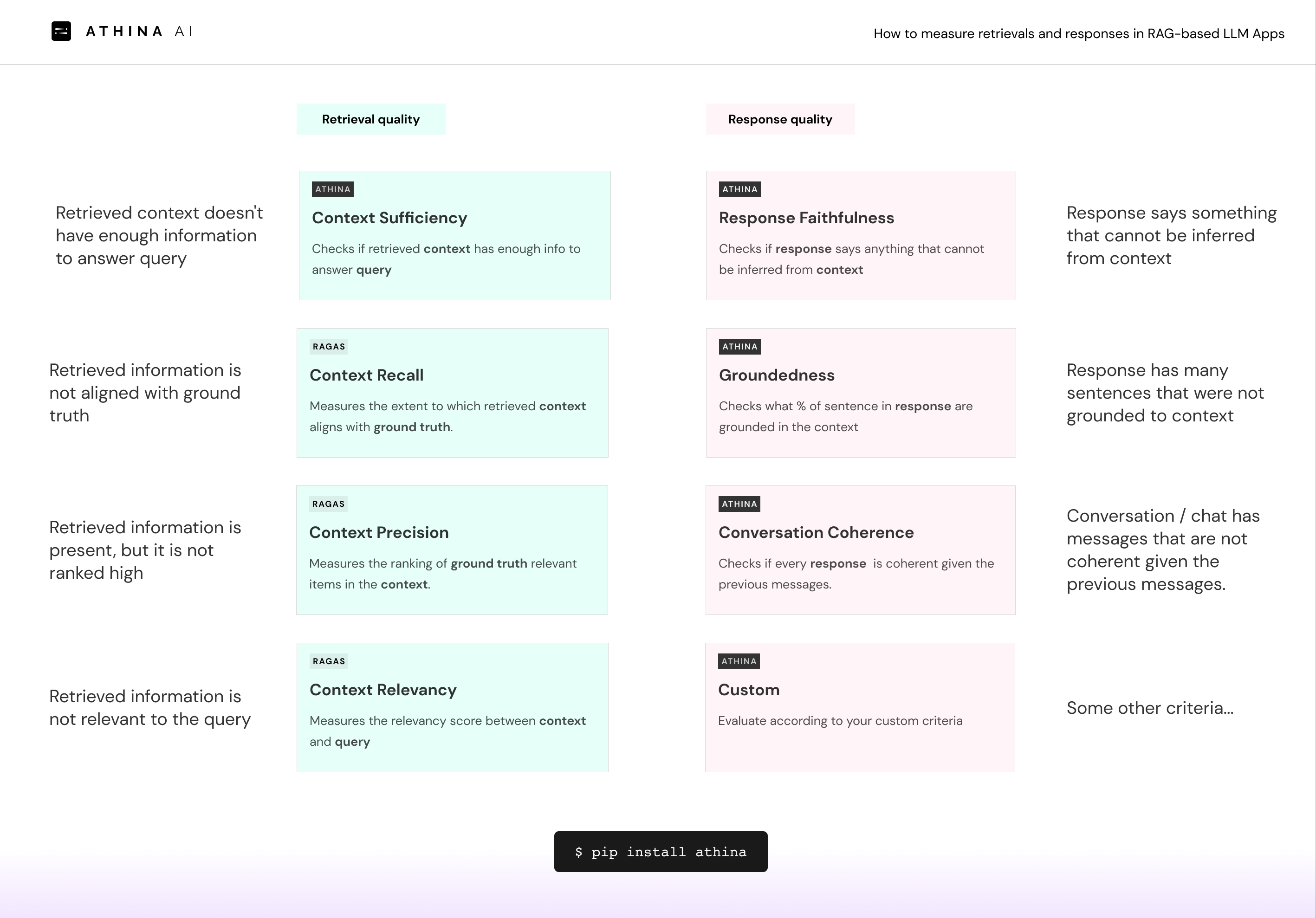
Bad retrieval
- Retrieved information is not aligned with ground truth (Context Recall)
- Retrievals are present but they are not ranked high (Context Precision)
- Retrieved information doesn't have enough information to answer query (Context Sufficiency)
- Retrieved information is not relevant to the query (Context Relevancy)
Bad outputs
- Response says something that cannot be inferred from context (Faithfulness)
- Response has many sentences that were not grounded to context. (Groundedness)
- Conversation / chat has messages that are not coherent given the previous messages. (Conversation Coherence))
- Some other criteria... (Custom Evaluation)
How to detect such issues
Just plug in the evaluators you need and run the evals on your dataset.from athina.evals import RagasContextPrecision, RagasAnswerCorrectness, RagasContextRelevancy, RagasContextRecall, RagasFaithfulness, Groundedness
import os
from athina import evals
from athina.loaders import Loader
from athina.keys import OpenAiApiKey
from athina.runner.run import EvalRunner
from athina.datasets import yc_query_mini
import pandas as pd
from dotenv import load_dotenv
load_dotenv()
OpenAiApiKey.set_key(os.getenv('OPENAI_API_KEY'))
# Load a dataset from list of dicts
raw_data = yc_query_mini.data
dataset = Loader().load_dict(raw_data)
# View dataset in a dataframe
pd.DataFrame(dataset)
# Define evaluation suite
model = "gpt-4-turbo-preview"
eval_suite = [
evals.RagasAnswerCorrectness(model=model),
evals.RagasContextPrecision(model=model),
evals.RagasContextRelevancy(model=model),
evals.RagasContextRecall(model=model),
evals.ContextContainsEnoughInformation(model=model),
evals.RagasFaithfulness(model=model),
evals.Faithfulness(model=model),
evals.Groundedness(model=model),
evals.DoesResponseAnswerQuery(model=model)
]
# Run the evaluation suite
batch_eval_result = EvalRunner.run_suite(
evals=eval_suite,
data=dataset,
max_parallel_evals=8
)
batch_eval_resultYou can run these evaluations in a python notebook, and view results in a dataframe like this: Example Notebook on Github (opens in a new tab)