Groundedness
This is an LLM Graded Evaluator
Github (opens in a new tab) | Example Notebook (opens in a new tab)
❊ Info
💡
Note: this evaluator is very similar to Faithfulness but it returns a metric between 0 and 1.
This evaluator checks if the LLM-generated response is grounded in the provided context.
For many RAG apps, you want to constrain the response to the context you are providing it (since you know it to be true). But sometimes, the LLM might use its pretrained knowledge to generate an answer. This is often the cause of "Hallucinations".
Default Engine: gpt-3.5-turbo
Required Args
context: The context that your response should be grounded toresponse: The LLM generated response
Metric:
Groundedness: Number of sentences in the response that are grounded in the context divided by the total number of sentences in the response.- 0: None of the sentences in the response are grounded in the context
- 1: All of the sentences in the response are grounded in the context
Example
- Context: Y Combinator was founded in March 2005 by Paul Graham and Jessica Livingston as a way to fund startups in batches. YC invests $500,000 in 200 startups twice a year.
- Response: YC was founded by Paul Graham and Jessica Livingston. They invests $500k in 200 startups twice a year. In exchange, they take 7% equity.
🚫
Eval Result
- Result: Fail
- Score: 0.67
- Explanation: There is no evidence of the following sentence in the context:
- "In exchange, they take 7% equity"
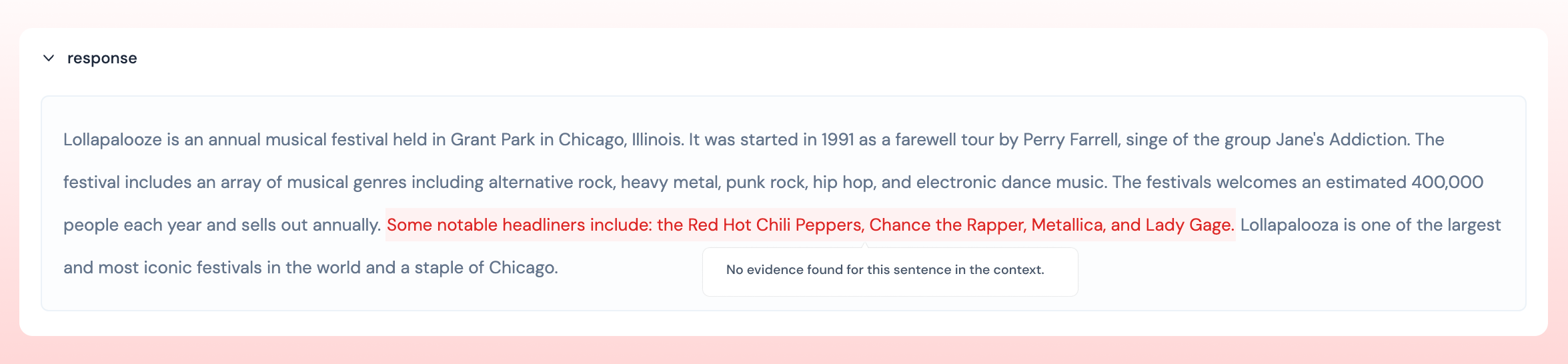
On Athina platform, in the Develop view, sentences that are not grounded in the context are highlighted in red.
▷ Run the eval on a dataset
- Load your data with the
RagLoader
from athina.loaders import RagLoader
# Load the data from CSV, JSON, Athina or Dictionary
dataset = RagLoader().load_json(json_file)- Run the evaluator on your dataset
from athina.evals import Groundedness
Groundedness().run_batch(data=dataset)▷ Run the eval on a single datapoint
Groundedness().run(
context=context,
response=response
)